Twitter System Design
Remember that guy who, purely by chance, liveblogged the Osama raid in 2011? Be it political campaigns, social movements, natural disasters, anything! Anything major happens and it is first reported on Twitter.
Which makes this a typical interview question for those in IT - “How would you design a system like Twitter”. Well, let’s design Twitter then!
Let’s look at the requirements to start with.
Functional Requirements
- Tweet - should allow you to post text, image, video, links, etc
- Re-tweet - should allow you to share someone’s tweets
- Follow - this will be a directed relationship. If we follow Barack Obama, he doesn’t have to follow us back
- Search
Non Functional Requirements
- Read heavy - The read to write ratio for twitter is very high, so our system should be able to support that kind of pattern
- Fast rendering
- Fast tweet.
- Lag is acceptable - From the previous two NFRs, we can understand that the system should be highly available and have very low latency. So when we say lag is ok, we mean it is ok to get notification about someone else’s tweet a few seconds later, but the rendering of the content should be almost instantaneous.
- Scalable - 5k+ tweets come in every second on twitter on an average day. On peak times it can easily double up. These are just tweets, and as we have already discussed read to write ratio of twitter is very high i.e. there will be an even higher number of reads happening against these tweets. That is a huge amount of requests per second.
So how do we design a system that delivers all our functional requirements without compromising the performance? Before we discuss the overall architecture, let’s split our users into different categories. Each of these categories will be handled in a slightly different manner.
- Famous Users: Famous users are usually celebrities, sportspeople, politicians, or business leaders who have a lot of followers
- Active Users: These are the users who have accessed the system in the last couple of hours or days. For our discussion, we will consider people who have accessed twitter in the last three days as active users.
- Live Users: These are a subset of active users who are using the system right now, similar to online on Facebook or WhatsApp..
- Passive Users: These are the users who have active accounts but haven’t accessed the system in the last three days.
- Inactive Users: These are the “deleted” accounts so to speak. We don’t really delete any accounts, it is more of a soft delete, but as far as the users are concerned the account doesn’t exist anymore.
Now, for simplicity, let us divide the overall architecture into three flows. We will separately look at the onboarding flow, tweet flow, and search and analytics side of the system.
Note: Remember how twitter is a very read-heavy system? Well, while designing a read-heavy system, we need to make sure that we are precomputing and caching as much as we can to keep the latency as low as possible.
System Architecture
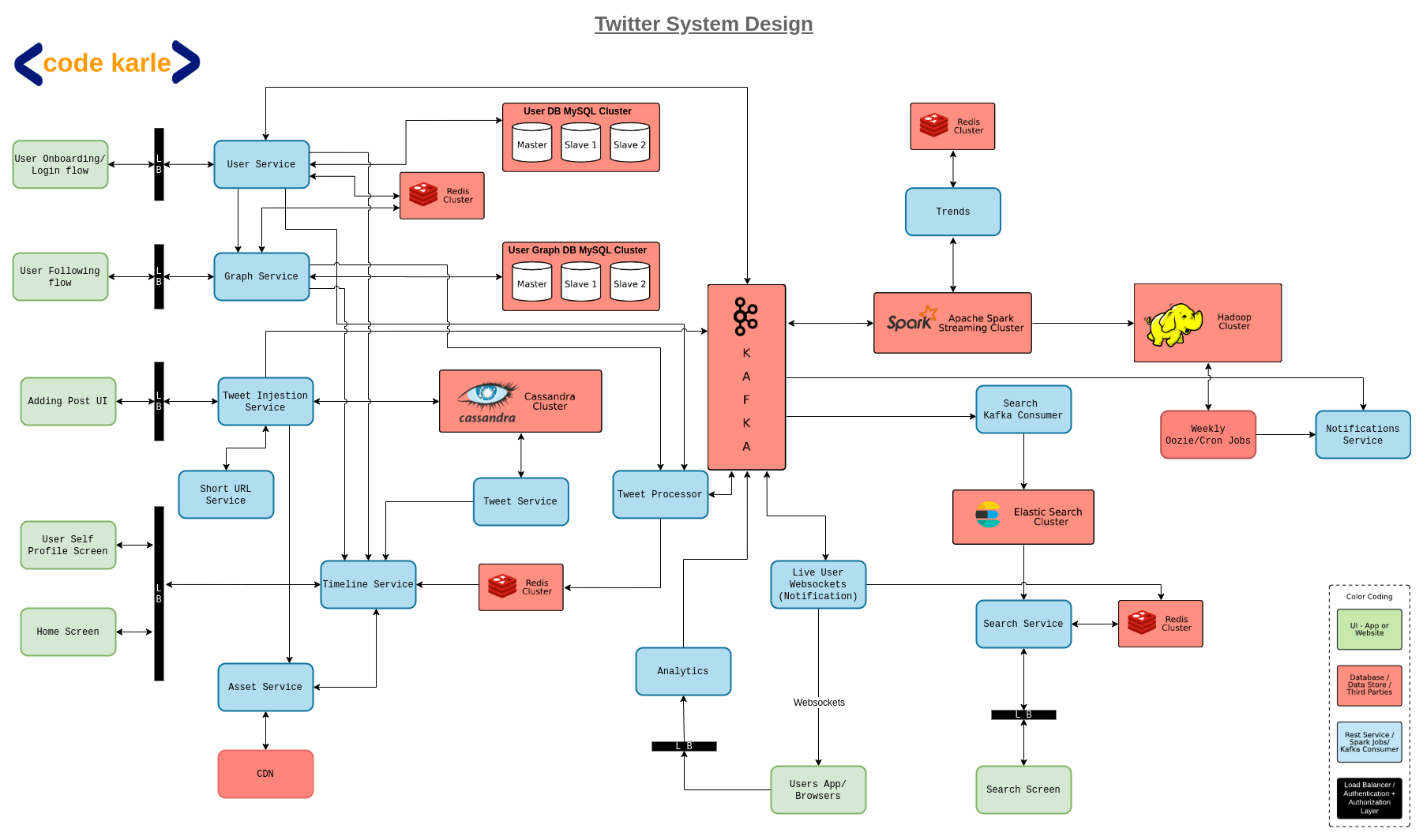
Onboarding flow
We have a User Service that will store all the user-related information in our system and provide endpoints for login, register, and any other internal services that need user-related information by providing GET APIs to fetch users by id or email, POST APIs to add or edit user information and bulk GET APIs to fetch information about multiple users. This user service sits on top of a User DB which is a MySQL database. We use MySQL here as we have a finite number of users and the data is very relational. Also, the User DB will mostly power the writes and the reads related to user details will be powered by a Redis cache which is an image of User DB. When user service receives a GET request with a user id, it will firstly lookup in the Redis cache, if the user is present in the Redis it will return the response. Otherwise, it will fetch the information from User DB, store it in Redis, and then respond to the client.
User-follow flow
The “follow” related requests will be serviced by a Graph Service, which creates a network of how the users are connected within the system. Graph service will expose APIs to add follow links, get users followed by a certain user-id or the users following a certain user-id. This Graph service sits on top of a User Graph DB which is again a MySQL DB. Again, the follow-links won’t change too frequently, so it makes sense to cache this information in a Redis. Now in the follow flow we can cache two pieces of information - who are the followers of a particular user, and who is the user following. Similar to the user service, when graph service receives a get request it will firstly lookup in the Redis. If Redis has the information it responds to the user. Otherwise, it fetches the information from the graph DB, stores it in Redis, and responds to the user.
Now, there are some things we can conclude based on a user’s interaction with Twitter, like their interests, etc. So when such events occur, an Analytics Service puts these events in a Kafka.
Now, remember our Live users? Say U1 is a live user following U2 and U2 tweets something. Since U1 is live, it makes sense that U1 gets notified immediately. This happens through the User Live Websocket service. This service keeps an open connection with all the live users, and whenever an event occurs that a live user needs to be notified of, it happens through this service. Now based on the user’s interaction with this service we can also track for how long the users are online, and when the interaction stops we can conclude that the user is not live anymore. When the user goes offline, through the websocket service an event will be fired to Kafka which will further interact with user service and save the last active time of the user in Redis, and other systems can use this information to accordingly modify their behavior.
Tweet flow
Now a tweet could contain text, images, videos, or links. We have something called an Asset service which takes care of uploading and displaying all the multimedia content in a Tweet. We have discussed the nitty-gritty of asset service in the Netflix design article, so check that out if you are interested.
Now, we know that tweets have a constraint of 140 characters which can include text and links. Thanks to this limit we cannot post huge URLs in our tweets. This is where a URL shortener service comes in. We are not going into the details of how this service works, but we have discussed it in our Tiny URL article, so make sure to check it out. Now that we have handled the links as well, all that is left is to store the text of a tweet and fetch it when required. This is where the tweet ingestion service comes in. When a user tries to post a tweet and hits the submit button, it calls the tweet ingestion service which stores the tweet in a permanent data store. We use Cassandra here because we will have a huge amount of tweets coming in every day and the query pattern we require here is what Cassandra is best for. To know more about why we use the database solutions we do check out our article about choosing the best storage solutions.

Now, the tweet ingestion service, as the name suggests, is only responsible for posting the tweets and doesn’t expose any GET APIs to fetch tweets. As soon as a tweet is posted, the tweet ingestion service will fire an event to Kafka saying a tweet id was posted by so and so user id. Now on top of our Cassandra, sits a Tweet service that will expose APIs to get tweets by tweet id or user id.
Now, let’s have a quick look at the users’ side of things. On the read-flow, a user can have a user timeline i.e. the tweets from that user or a home timeline i.e. tweets from the people a user is following. Now a user could have a huge list of users they are following, and if we make all the queries at runtime before displaying the timeline it will slow down the rendering. So we cache the user’s timeline instead. We will precalculate the timeline of active users and cache it in a Redis, so an active user can instantaneously see their timeline. This can be achieved with something called a Tweet processor.
As mentioned before, when a tweet is posted, an event is fired to Kafka. Kafka communicates the same to the tweet processor and creates the timeline for all the users that need to be notified of this recent tweet and cache it. To find out the followers that need to be notified of this change tweet service interacts with the graph service. Suppose user U1, followed by users U2, U3, and U4 posts a tweet T1, then the tweet processor will update the timelines for U2, U3, and U4 with tweet T1 and update the cache.
Now, we have only cached the timelines for active users. What happens when a passive user, say P1, logs in to the system? This is where the Timeline Service comes in. The request will reach the timeline service, timeline service will interact with the user service to identify if P1 is an active user or a passive user. Now since P1 is a passive user, its timeline is not cached in Redis. Now the timeline service will talk to the graph service to find a list of users that P1 follows, then queries the tweet service to fetch tweets of all those users, caches them in the Redis, and responds back to the client.
Now we have seen the behavior for active and passive users. How will we optimize the flow for our live users? As we have previously discussed, when a tweet is successfully posted an event will be sent to Kafka. Kafka will then talk to the tweet processor which creates timelines for active users and saves them in Redis. But here if the tweet processor identifies that one of the users that need to be updated is a live user, then it will fire an event to Kafka which will now interact with the live websocket service we briefly discussed before. This websocket service will now send a notification to the app and update the timeline.
So now our system can successfully post tweets with different types of content and has some optimization built in to handle active, passive, and live users in a somewhat different manner. But it is still a fairly inefficient system. Why? Because we completely forgot about our famous users! If Donald Trump has 75 million followers, then every time Trump tweets about something, our system needs to make 75 million updates. And this is just one tweet from one user. So this flow will not work for our famous users.
Redis cache will only cache the tweets from non-famous users in the precalculated timelines. Timeline service knows that Redis only stores tweets from normal users. It interacts with graph service to get a list of famous users followed by our current user, say U1, and it fetches their tweets from the tweet service. It will then update these tweets in Redis and add a timestamp indicating when the timeline was last updated. When the next request comes from U1, it checks if the timestamp in Redis against U1 is from a few minutes back. If so, it will query the tweet service again. But if the timestamp is fairly recent, Redis will directly respond back to the app.
Now we have handled active, passive, live, and famous users. As for the inactive users, they are already deactivated accounts so we need not worry about them.
Now what happens when a famous user follows another famous user, let’s say Donald Trump and Elon Musk? If Donald Trump tweets, Elon musk should be notified immediately even if the other non-famous users are not notified. This is handled by the tweet processor again. Tweet processor, when it receives an event from Kafa about a new tweet from a famous user, let’s say, Donald Trump, updates the cache of the famous users that follow Trump.
Now, this looks like a fairly efficient system, but there are some bottlenecks. Like Cassandra - which will be under a huge load, Redis - which needs to scale efficiently as it is stored completely in RAM, and Kafka - which again will receive crazy amounts of events. So we need to make sure that these components are horizontally scalable and in case of Redis, don’t store old data that just unnecessarily uses up memory.
Now coming to search and analytics!
Remember the tweet ingestion service we discussed in the previous section? When a tweet is added to the system, it fires an event to Kafka. A search consumer listening to Kafka stores all these incoming tweets into an Elasticsearch database. Now when the user searches a string in Search UI, which talks to a Search Service. Search service will talk to elastic search, fetch the results, and respond back to the user.
Now assuming an event occurred and people are tweeting or searching about it on Twitter, then it is safe to assume that more people will search for it. Now we shouldn’t have to query the same thing again and again on elasticsearch. Once the search service gets some results from elasticsearch, it will save them in Redis with a time-to-live of 2-3 minutes. Now when the user searches something, Search service will firstly lookup in Redis. If the data is found in Redis it will be responded back to the user, otherwise, the search service will query elasticsearch, get the data, store it in Redis, and respond back to the user. This considerably reduces the load on elasticsearch.
Let’s go back to our Kafka again. There will be a spark streaming consumer connected to Kafka which will keep track of trending keywords and communicate them to the Trends service. This could further be connected to a Trend UI to visualize this data. We don’t need a permanent data store for this information as trends will be temporary but we could use a Redis as a cache for short-term storage.
Now you must have noticed we have used Redis very heavily in our design. Now even though Redis is an in-memory solution, there is still an option to save data to disk. So in case of an outage, if some of the machines go down, you still have the data persisted on the disk to make it a little more fault-tolerant.
Now, other than trends there is still some other analytics that can be performed like what are people from India talking about. For this, we will dump all the incoming tweets in a Hadoop cluster, which can power queries like the most re-tweeted posts, etc. We could also have a weekly cron job running on the Hadoop cluster, which will pull in the information about our passive users and send out a weekly newsletter to them with some of the most recent tweets that they might be interested in. This could be achieved by running some simple ML algorithms that could tell the relevance of tweets based on the previous searches and reads by the users. The newsletters can be sent via a notification service that can talk to user service to fetch the email ids of the users.
That should be it for Twitter System Design! Send in your thoughts on our youtube video!