Uber System Design
Booking a cab on Uber might take as little as 1-2 minutes, but there is a huge architecture that supports each and every step involved from entering our location to finally booking the cab! What actually happens when we book a cab on Uber or Ola or Lyft? Well, let us have a look. Let us design a cab booking application.
Before we begin, let us first finalize the requirements.
Functional Requirements
- See cabs in your vicinity
- ETA and approximate price
- Book a cab
- Location tracking
Non-Functional Requirements
- Global
- Low latency
- High availability
- High consistency
- Scalable
Note: High availability and consistency at the same time seem to violate the cap theorem which states that a distributed system can either be highly available or consistent. But not all the components need to be consistent and available at the same time, some need to be consistent, and some need to be available.
Now anyone who has booked a cab using uber knows that they map our location and finds some drivers in the customer’s vicinity to book the cab. How does that work though?
Well, we use something called a segment. Think of segment as a rectangular area that is easy to operate on such that a larger area, say a city, has been divided into multiple segments. Based on the coordinates of segment boundaries and coordinates of a cab, it should be easy enough to point out which segment the cab falls in. Similarly, it should be easy enough to assign a segment to our customers. Now we need to keep in mind that cabs are continuously moving and keep changing segments, so we need to get continuous pings from the cab at runtime so we can accurately assign segments to the cabs. This segment mapping and management for our customers and cabs will be taken care of by a map service. Map service, along with mapping and managing segments for users and cabs, will also find the ETA and route from the cab's current location to the user’s pick-up location.

This map service is discussed in more detail in our Google map system design article so make sure to check that out. Now as we know, there are some peak traffic areas where there will be a huge number of cabs and some areas with much less traffic and fewer cabs. And how easy it is to manage a segment is somewhat dependent on how many cabs are available in the area. In such a case, map service will divide high cab availability segments into smaller segments and merge lower cab availability segments into one bigger segment, so that the segments are now more efficiently managed.
Before going into the detailed architecture of the application, let us briefly look at how customers and drivers interact with the system.
All the users will interact with the system via a user app that talks to user service. User service is a repository of all user-related information and exposes APIs to fetch or update all user-related information. It sits on a MySQL based User DB and caches the same information in a Redis.
Now when the user is trying to book a cab, the flow will be powered by a cab request service. Cab request service interacts with a cab finder service, to book a cab, and to fetch the details of the booked cab.
But our app will not just service the customers booking cabs! What about the cab drivers who are getting customers through our app? The cab drivers will be interacting with the system via a driver app. The driver app will interact with the driver service, which is a driver counterpart of the user service. Driver service will again sit on top of a MySQL based Driver DB and cache the same information in a Redis. Now driver app will also talk to a location service through a series of WebSocket servers.
Now, remember how we discussed that the driver’s live location will be shared with the system every few minutes and communicated to the map service for further segment management? This happens via the location service. Location service gets the driver’s location and further queries the map service to find the driver segment, and book the cab accordingly.
So we have seen how the customer interacts with the app, and how the driver interacts with the app. But how do these two flows come together to give a seamless experience on both ends? Let’s have a look!
System Architecture
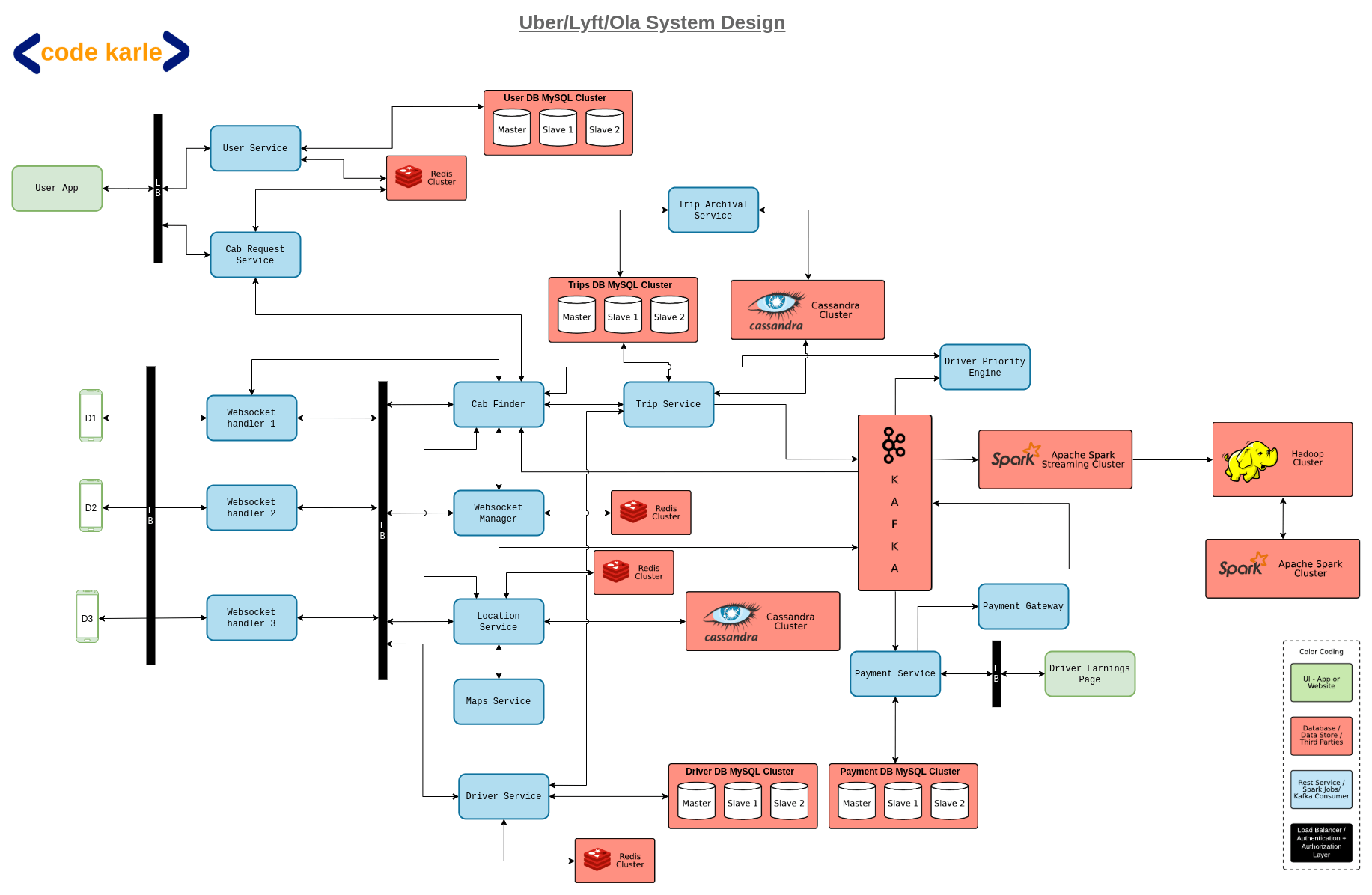
All the active drivers who are ready to accept trips are connected to a WebSocket handler. Websocket handlers will keep an open connection with the drivers to get location pings, or to send notifications about trips, etc. These WebSocket handlers are connected to a WebSocket manager which keeps track of which WebSocket handlers are connected to which drivers in a Redis. Redis won’t just act as an in-memory solution here, but will also persist the data on to a disk to make it a bit more fault-tolerant. Redis, along with keeping track of which host is connected to which driver, will also keep a reverse mapping for which driver is connected to which host.
Now, the driver apps will send location pings of the drivers every few seconds, which is managed by the location service. The location service will store the location information in a Cassandra. Other than the driver’s last known location, location service will also keep track of the route followed by the driver while on a trip for billing or auditing purposes. Location service also talks to a map service to figure out which segment the driver belongs to and updates in Redis the mapping of which drivers belong in which segments.
The next component we have is something called a trip service, which is a repository of all trip-related information. It sits on top of a MySQL Trips DB and a Cassandra. The MySQL stores information about all the trips that are about to start or are in progress. Once the trip completes this information is moved to Cassandra.
But why do we need this kind of data storage? Why not just MySQL or just Cassandra? Well, we can’t just use MySQL because it will over time become massive data. But the data we store against each trip is very relational and will be distributed across multiple tables and also needs to be consistent across all tables. Hence as long as the information is bound to be updated we will store it in a MySQL DB and once the trip completes we move it to Cassandra. This movement from MySQL to Cassandra is taken care of by a trip archiver, which runs a scheduled job for the same.
Now trip service, as we mentioned before, exposes all trip-related APIs, for example getting trips by driver id, getting trips completed in the last couple of days, etc.
But where is the customer in this flow? Well as previously mentioned, the customer app makes the request to cab request service with their pickup and drop location, which further talks to cab finder service. Cab finder gets a driver who will make the trip and sends the trip and driver information back to the cab request service. Cab finder will also put an event into Kafka about whether or not it was successfully able to find a driver and perform some analytics based on this information. But we will look at that later.
First let's look at how exactly does the cab finder find the driver? Well, the cab finder has the coordinates of the user’s pick up location. With those coordinates it will talk to the map service, to fetch the segment of the pick-up location. Then it queries surrounding segments as well and finds the drivers closest to the customer.
Now, we also have a concept of modes here. Eg, if it is a premium customer, then we will assign the trip to the best driver, if it is an average customer we may choose to broadcast to all the drivers about the trip and assign the trip to whoever accepts the trip first. The concept of modes is also implemented by the cab finder. And the driver-related information that is required for responding to these modes is provided by something called a driver priority engine. So at this point cab finder will talk to the driver priority engine to sort the drivers according to the mode’s requirement. Once it has this list of drivers it will choose the most suitable driver, say D1, for the trip and talks to the web socket manager to find the web socket handler that is connected D1. Now it will talk to the relevant handler, WSH1 in this case, and notify D1 about the trip. At the same time, the customer will be notified via cab request service that D1 has been assigned for their trip. Now once the driver is assigned, the cab finder will talk to the trip service to create a trip with the customer id, driver id, and other relevant information.
Now let's come to the Analytics side of this!
Throughout the booking flow, Kafka will continue to get events about location, if cabs were booked or not, updates about the trip, etc. So what happens to these events? Well, a payment service will sit on top of Kafka which listens to the trip completion event. As soon as the trip is completed, based on distance, time, etc it will come up with the amount of the money that needs to be paid and it inserts all this information in a Payment MySQL DB. The payment service will also be connected with a payment gateway in case the payment method requires so. It will also expose APIs to give all the previous payments-related information for the customer’s or driver’s account.
Another consumer linked to Kafka is a spark streaming cluster, which keeps track of basic events like drivers not found, identifying areas with scarcity of drivers, and other basic analytics. This spark streaming cluster will also dump all the events in a Hadoop cluster for further analytics like user profiling, driver profiling, etc to classify customers or drivers as premium or regular. Similarly, the driver profile engine that we discussed before which will classify the drivers based on ratings, ETA accuracy, etc to score the drivers will be powered by the same data
We could also have a fraud engine running on the same information. For example, if the same driver is always taking trips from the same user, there is a high chance that they are friends or the same person trying to exploit any incentive programs offered by our application. We could also use this same data to fetch the traffic or road condition information that can further power the map service.
That should be it for Uber System Design! Send in your thoughts on our youtube video!